Edytujesz film z udziałem wielu prelegentów, może to być podcast lub wywiad. Ręczne dodawanie napisów jest żmudne — musisz słuchać, pisać i synchronizować każde wypowiadane słowo. Co by było, gdyby Twój edytor wideo mógł automatycznie rozpoznawać różne głosy i generować napisy dla każdego mówcy? W tym miejscu rozpoznawanie mówcy w Pythonie zmienia grę.
Python to najchętniej wybierany język programowania do tworzenia aplikacji głosowych dzięki solidnym bibliotekom. Biblioteki te pomagają we wdrażaniu i wdrażaniu modeli rozpoznawania mówców na potrzeby przetwarzania mowy w czasie rzeczywistym, analizy i identyfikacji mówcy. Na przykład zestaw SDK Pico Voice Eagle zapewnia szybką i precyzyjną identyfikację mówcy w aplikacjach opartych na sztucznej inteligencji.
Alternatywnie istnieją platformy do edycji wideo, które integrują sztuczną inteligencję rozpoznawania mowy. Działają poprzez skanowanie dźwięku filmu, rozróżnianie mówców i generowanie zsynchronizowanych napisów.
W tym przewodniku dowiesz się, jak zaimplementować identyfikację mówcy w Pythonie. Przyjrzymy się także najlepszym, niewymagającym kodu alternatywom umożliwiającym łatwe tworzenie napisów do filmów.

W tym artykule
- Podstawy przetwarzania dźwięku
- Identyfikacja mówcy w czasie rzeczywistym za pomocą pakietu SDK Picovoice Eagle
- Czy istnieją prostsze sposoby rozpoznawania mówiącego?
- Gdzie mogę korzystać z aplikacji do rozpoznawania osób mówiących?
Część 1:Podstawy przetwarzania dźwięku

Każdy system rozpoznawania głosu rozpoczyna się od przetwarzania dźwięku. Dźwięk przemieszcza się w postaci ciągłych sygnałów analogowych, ale komputery wymagają formatów cyfrowych. Aby przekształcić mowę w dane, używamy częstotliwości próbkowania i technik kodowania dźwięku.
Częstotliwość próbkowania określa, jak często dźwięk jest rejestrowany na sekundę. Standard rozpoznawania osób mówiących w Pythonie wynosi 16 kHz, co zapewnia wysoką dokładność. Format pliku audio również ma znaczenie — popularne są formaty WAV, MP3 i FLAC, przy czym w przypadku zadań związanych z uczeniem maszynowym preferowany jest format WAV.
Python upraszcza identyfikację mówcy w czasie rzeczywistym dzięki wyspecjalizowanym bibliotekom, takim jak PyAudio i Picovoice Eagle SDK. Korzystając z tych narzędzi, programiści mogą przechwytywać, analizować i trenować modele na potrzeby identyfikacji mówców w czasie rzeczywistym w Pythonie.
Część 2:Identyfikacja mówcy w czasie rzeczywistym za pomocą pakietu SDK Picovoice Eagle
Picovoice Eagle SDK to wydajne narzędzie do rozpoznawania mówcy w Pythonie . W odróżnieniu od tradycyjnych modeli przetwarza dźwięk lokalnie. Ten pakiet SDK ma kluczowe znaczenie dla identyfikacji mówcy w czasie rzeczywistym w Pythonie, szczególnie w systemach bezpieczeństwa AI i inteligentnych asystentach.
Co więcej, jest lekki i bezproblemowo działa na wielu platformach, w tym Windows, macOS, Linux, Android, iOS, a nawet Raspberry Pi. Wystarczy zarejestrować się w konsoli Pico Voice i uzyskać klucz dostępu, aby uwierzytelnić swoje użycie.
Instalowanie i konfigurowanie pakietu SDK Pico Voice Eagle w języku Python
Aby zintegrować pakiet SDK Picovoice Eagle do rozpoznawania osób mówiących w języku Python, zainstaluj go najpierw. Zanim to zrobisz, upewnij się, że masz zainstalowany Python 3.6 lub nowszy.
Otwórz terminal (Linux/macOS) lub wiersz poleceń (Windows) i uruchom:
lub
Jeśli Python jest zainstalowany, wyświetli się coś takiego:
Jeśli wersja to 3.6 lub nowsza, wszystko gotowe.
Na początek zainstaluj niezbędne biblioteki. Uruchom następujące polecenie w swoim terminalu:
pip install Rozpoznawanie mowy pyaudio librosa rejestrator pv
W przypadku pakietu SDK Picovoice Eagle pobierz i zainstaluj:
pip install pvporcupine pveagle
Przewodnik krok po kroku dotyczący wdrażania identyfikacji mówcy w czasie rzeczywistym przy użyciu zestawu SDK Picovoice Eagle w języku Python
- Krok 1:Zainstaluj Pythona. Na oficjalnej stronie Pythona wybierz opcję pobrania najnowszej wersji Pythona 3. x.x.
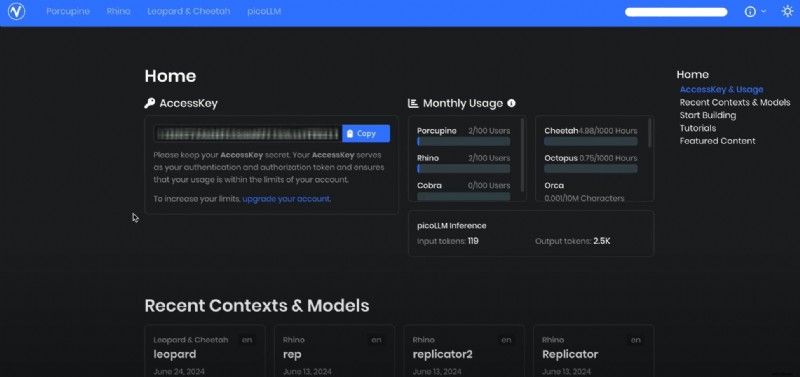
- Krok 2: Następnie zarejestruj bezpłatne konto Picovoice Console i odzyskaj klucz dostępu. Ten klucz jest wymagany do uwierzytelniania Twoich żądań podczas korzystania z pakietu SDK Eagle Speaker Recognition.
- Krok 3: Zainstaluj niezbędne pakiety Pythona. Uruchom następujące polecenie w terminalu:
pip zainstaluj pveagle pvrecorder
Spowoduje to zainstalowanie PV Eagle (do rozpoznawania głośników) i PV Recorder (do przechwytywania dźwięku).
- Krok 4: Utwórz dwa pliki w swoim VsCode. Pierwszym plikiem będzie rejestracja prelegenta. Rejestracja to proces tworzenia profilu głośnika na podstawie danych głosowych. Wykonaj następujące kroki:
- Zaimportuj wymagane biblioteki
- Zainicjuj EagleProfile za pomocą klucza dostępu
- Użyj rejestratora PV do przechwytywania próbek głosu
- Przesyłaj ramki audio do EagleProfile do momentu zakończenia rejestracji
- Eksportuj profil głośnika do późniejszego rozpoznania
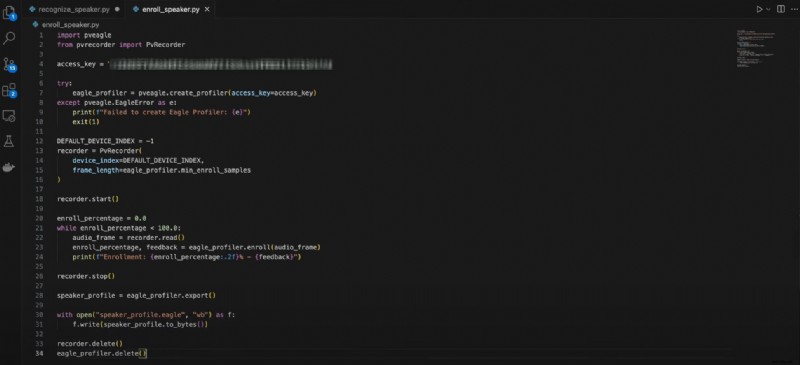
Oto kod umożliwiający rejestrację prelegentów:
importuj pveaglez pvrecorder zaimportuj PvRecorder
access_key =„TWÓJ_KLUCZ DOSTĘPU”
spróbuj:
eagle_profiler =pveagle.create_profiler(klucz_dostępu=klucz_dostępu)
z wyjątkiem pveagle.EagleError jako e:
print(f"Nie udało się utworzyć Eagle Profilera:{e}")
wyjście(1)
DEFAULT_DEVICE_INDEX =-1
rejestrator =PvRecorder(
indeks_urządzenia=DEFAULT_DEVICE_INDEX,
długość_ramki=eagle_profiler.min_enroll_samples
)
rejestrator.start()
procent_rejestracji =0,0
podczas gdy procent_rejestracji <100,0:
audio_frame =rejestrator.read()
enroll_percentage, feedback =eagle_profiler.enroll(audio_frame)
print(f"Rejestracja:{enroll_percentage:.2f}% - {feedback}")
rejestrator.stop()
speaker_profile =eagle_profiler.export()
z open("speaker_profile.eagle", "wb") jako f:
f.write(speaker_profile.to_bytes())
rejestrator.usuń()
eagle_profiler.delete()
- Krok 5:Przejdź do terminala i zarejestruj, wpisując poniższy kod
python3 enroll_speaker.py
Po uruchomieniu skryptu spróbuj mówić do mikrofonu. Jeśli Twój głos pasuje do profilu zarejestrowanego głośnika, zostanie wyświetlony komunikat „Rozpoznano głośnik!” W przeciwnym razie wskaże nieznanego mówcę.

- Krok 6: Teraz, gdy profil głośnika jest gotowy, utwórzmy kod do rozpoznawania mówcy w czasie rzeczywistym w drugim pliku. Spowoduje to załadowanie profilu głośnika i rozpoznanie go w czasie rzeczywistym za pomocą pakietu SDK Pico Voice Eagle.
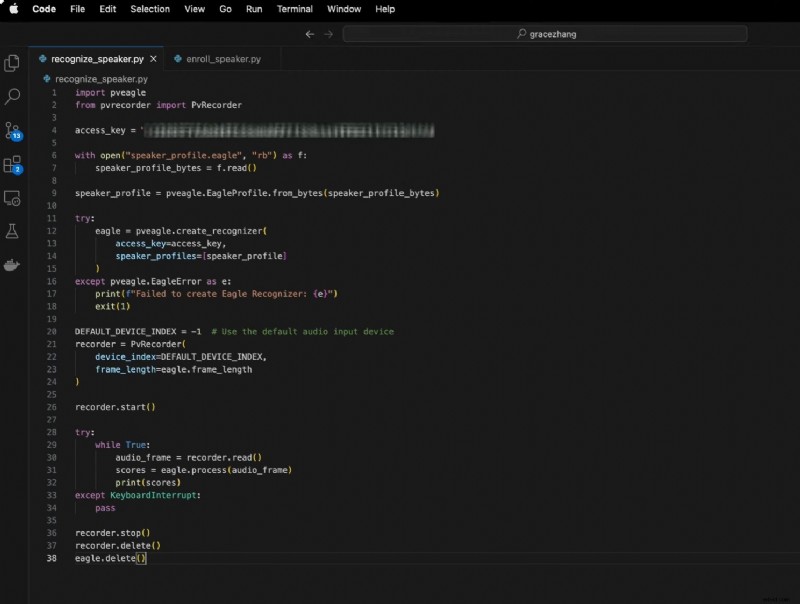
Obejmuje to:
- Tworzenie instancji Eagle przy użyciu klucza dostępu i profilu głośnika
- Używanie rejestratora PV do przechwytywania dźwięku na żywo
- Przekazywanie ramek audio do Eagle w celu rozpoznania w czasie rzeczywistym
Oto kod:
importuj pveaglez pvrecorder zaimportuj PvRecorder
access_key =„TWÓJ_KLUCZ DOSTĘPU”
z open("speaker_profile.eagle", "rb") jako f:
speaker_profile_bytes =f.read()
speaker_profile =pveagle.EagleProfile.from_bytes(speaker_profile_bytes)
spróbuj:
orzeł =pveagle.create_recognizer(
klucz_dostępu=klucz_dostępu,
speaker_profiles=[speaker_profile]
)
z wyjątkiem pveagle.EagleError jako e:
print(f"Nie udało się utworzyć Eagle Recognizer:{e}")
wyjście(1)
DEFAULT_DEVICE_INDEX =-1 # Użyj domyślnego urządzenia wejściowego audio
rejestrator =PvRecorder(
indeks_urządzenia=DEFAULT_DEVICE_INDEX,
długość_ramki=eagle.długość_ramki
)
rejestrator.start()
spróbuj:
podczas gdy Prawda:
audio_frame =rejestrator.read()
wyniki =eagle.process(audio_frame)
drukuj (partytury)
z wyjątkiem przerwania klawiatury:
przejść
rejestrator.stop()
rejestrator.usuń()
orzeł.delete()
- Krok 7:Przetestuj i uruchom aplikację.
Python3 recognize_speaker.py
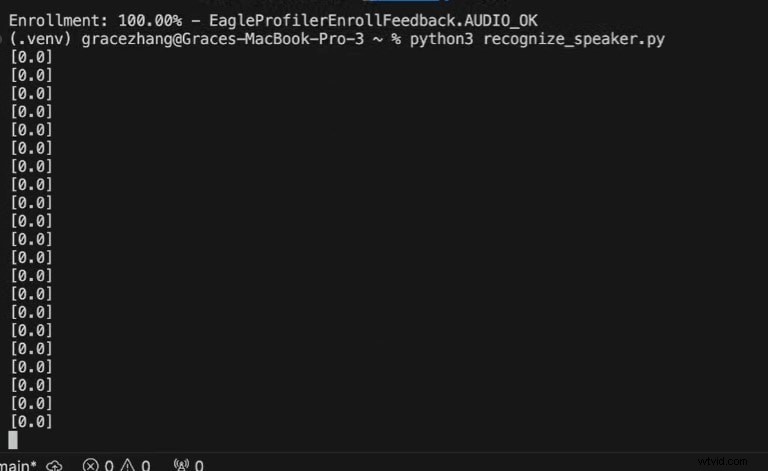
0 =Głos nie został rozpoznany
1 =Głos rozpoznany

Uwaga:w przeciwieństwie do modeli opartych na chmurze, Picovoice Eagle SDK przetwarza dane lokalnie. Zapewnia to szybsze wyniki, lepszą prywatność i brak zależności od Internetu.
Identyfikację mówcy w Pythonie mogą zrozumieć i wykonać tylko profesjonalni programiści. Aby zrozumieć proces, musisz mieć w pewnym stopniu wiedzę z zakresu programowania.
Część 3:Czy istnieją prostsze sposoby rozpoznawania mówiącego?
Stworzenie systemu rozpoznawania osób mówiących w języku Python wymaga umiejętności kodowania i wiedzy technicznej. Chociaż identyfikacja w Pythonie jest potężna, może stanowić wyzwanie dla osób niebędących programistami. Wielu użytkowników woli gotowe narzędzia, które oferują podobne funkcje mówiącego i rozpoznawania mowy. Jest to lepszy sposób na wykonanie zadania bez umiejętności kodowania.
Jednym z takich narzędzi jest WondershareFilmora, edytor wideo z wbudowanym rozpoznawaniem mówcy i edycją mowy. Umożliwia użytkownikom wykrywanie, transkrypcję i modyfikowanie nagrań głosowych bez pisania ani jednej linii kodu.
W przeciwieństwie do rozpoznawania mówców w Pythonie, które wymaga ręcznego szkolenia modelu, wbudowane narzędzia Filmory automatyzują ten proces. Możesz edytować i ulepszać pliki audio bez konieczności posiadania wiedzy na temat Pythona lub uczenia maszynowego. Dzięki temu identyfikacja mówcy jest dostępna dla twórców treści, marketerów i użytkowników biznesowych.
Funkcje wykrywania głośników mobilnych i edycji mowy firmy Filmora
Filmora integruje narzędzie oparte na sztucznej inteligencji, które upraszcza edycję dźwięku i rozpoznawanie mówców. Dzięki wersji mobilnej użytkownicy mają dostęp do funkcji wykrywania mówcy i edytowania mowy.
- Wykrywanie głośników. Wykrywanie głośników analizuje dźwięk i rozróżnia różne głośniki. Zamiast ręcznego słuchania i oznaczania głosów sztuczna inteligencja identyfikuje, kto i kiedy mówi.
- Edycja mowy. Edycja mowy może być żmudna, ale edycja mowy Filmory upraszcza ten proces. Pozwala użytkownikom zmieniać nagrania głosowe, dostosowywać klarowność i usuwać szumy tła.
Jak rozpoznawać głos, konwertować na tekst i edytować za pomocą Filmory w podróży
Filmora ułatwia rozpoznawanie mówców za pomocą kilku kliknięć. Oto przewodnik krok po kroku:
- Krok 1:Pobierz Filmorę, kliknij „nowy projekt i zaimportuj wideo z głosem.
- Krok 2:Wybierz tekst, aby przekonwertować wypowiadane słowa na tekst.

- Krok 3:Kliknij napisy AI, aby rozpocząć proces rozpoznawania głosu
- Krok 4: Kliknij opcję Wykrywanie mówcy przed wybraniem opcji Dodaj podpisy
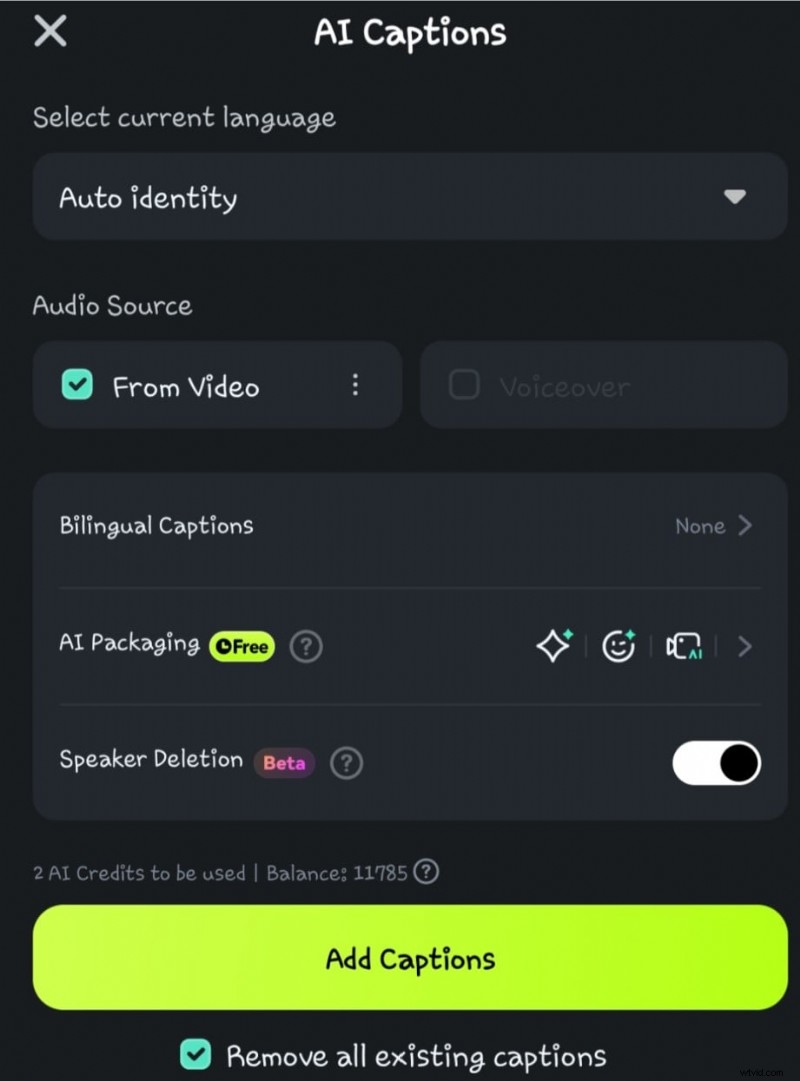
- Krok 5: Poczekaj, aż sztuczna inteligencja przetworzy zamianę głosu na tekst
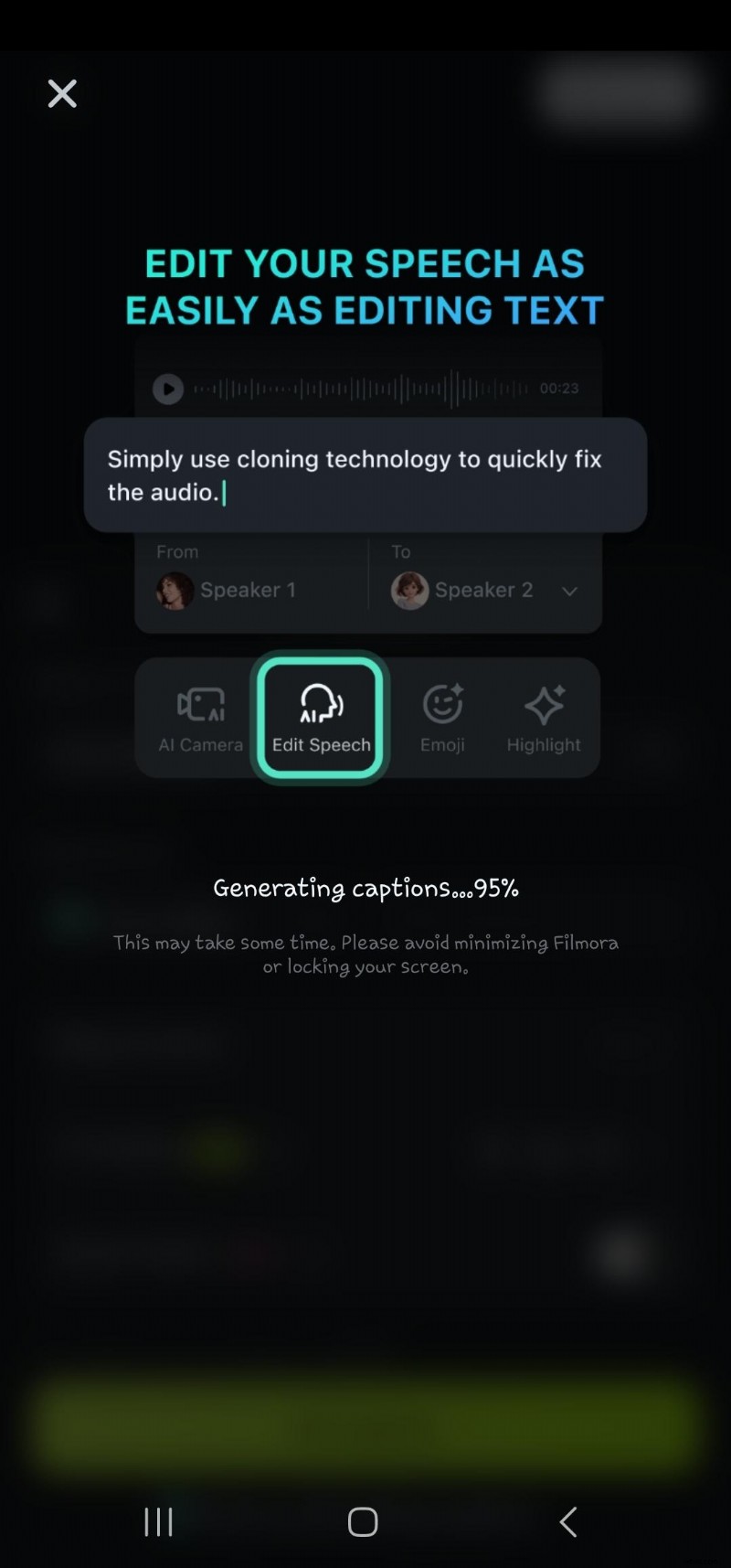
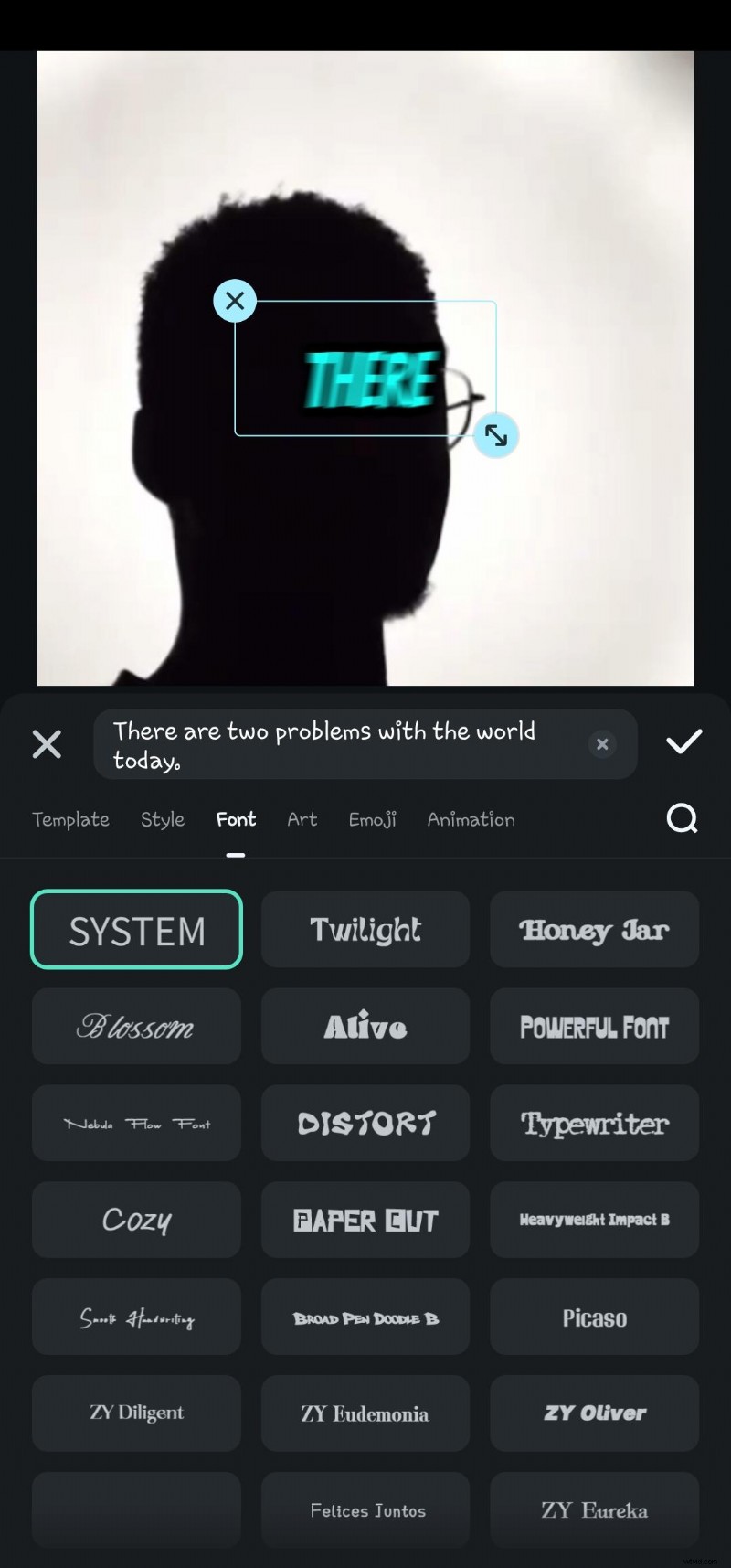
- Krok 6:Kliknij dwukrotnie wygenerowany tekst na osi czasu, aby przejść do opcji edycji mowy. Tutaj możesz dodać animację, zmienić szablon tekstu, czcionkę, styl, grafikę itp.
- Krok 7:Eksportuj wideo
Uwaga:musisz zrozumieć, że rozpoznawanie mówców w języku Python zapewnia pełną kontrolę nad uczeniem modeli. Ale Filmora zapewnia zautomatyzowane podejście. Funkcja AI zapewnia skuteczne rozpoznawanie mówcy bez konieczności skomplikowanego programowania.
Część 4:Gdzie mogę korzystać z aplikacji do rozpoznawania mówców?

Rozpoznawanie mówców w Pythonie bez wątpienia zmienia różne branże. Technologia ta zapewnia szybki i niezawodny sposób identyfikacji głosów w filmach i plikach audio. Staje się podstawową częścią różnych gałęzi przemysłu. Poniżej znajdują się obszary, w których te aplikacje mają zastosowanie.
- Inteligentni asystenci i urządzenia sterowane głosem. Aplikacje takie jak Siri, Alexa i Google Assistant wykorzystują identyfikację mówiącego do rozróżniania głosów. Umożliwia to spersonalizowanie odpowiedzi, bezpieczny dostęp i niestandardowe polecenia głosowe dla różnych użytkowników.
- Bezpieczeństwo i uwierzytelnianie głosowe. Wiele firm korzysta z identyfikacji mówców w celu weryfikacji użytkowników i zapobiegania oszustwom. Eliminuje zależność od hasła, poprawiając jednocześnie ochronę danych i wygodę użytkownika.
- Transkrypcja i notatki ze spotkań oparte na sztucznej inteligencji. Rozpoznawanie mówców pomaga aplikacjom takim jak Otter.ai różnicować mówców. Zwiększa to dokładność transkrypcji, zwłaszcza tych zawierających kilka notatek głosowych.
- Centra telefoniczne i obsługa klienta. Centra obsługi telefonicznej korzystają z rozpoznawania osób mówiących w języku Python, aby usprawnić uwierzytelnianie i wykrywanie klientów. Systemy oparte na sztucznej inteligencji identyfikują osoby dzwoniące za pomocą głosu, co ogranicza potrzebę ręcznej weryfikacji tożsamości. Poprawia to bezpieczeństwo, wydajność i czas reakcji obsługi klienta.
- Opieka zdrowotna i dostępność. Szpitale i aplikacje związane z opieką zdrowotną korzystają z identyfikacji osoby mówiącej w celu bezpiecznego uwierzytelniania pacjentów. Narzędzia AI oparte na głosie pomagają osobom o ograniczonej sprawności ruchowej uzyskać dostęp do urządzeń bez fizycznej interakcji. Rozpoznawanie mówców w języku Python zapewnia bezpieczny dostęp medyczny i poprawia opiekę nad pacjentem.
Wniosek
Python to jeden z najpopularniejszych języków służących do identyfikacji mówcy i głosu. Udostępnia potężne biblioteki, takie jak SpeechRecognition, PyAudio, Librosa i Pico Voice Eagle SDK.
Narzędzia te umożliwiają wysoką dokładność i identyfikację mówcy w Pythonie w czasie rzeczywistym . To sprawia, że jest to najlepsza opcja dla programistów, badaczy sztucznej inteligencji i aplikacji zabezpieczających. Filmora oferuje łatwiejszą alternatywę dla osób bez umiejętności programowania. Zapewnia konwersję mowy na tekst, edycję głosu i rozpoznawanie mówcy bez konieczności kodowania w języku Python.
Wypróbuj narzędzia Filmora oparte na sztucznej inteligencji do automatycznej edycji i transkrypcji głosu. Dzięki nim proces jest szybki i przyjazny.

Filmora
⭐⭐⭐⭐⭐
Najlepsze oprogramowanie i aplikacja do edycji wideo oparte na sztucznej inteligencji