Czy nadchodzący DeepSeek V4 powtórzy historię, czy ją przebije? DeepSeek kiedyś zszokował branżę sztucznej inteligencji, udowadniając, że nie potrzeba 100 milionów dolarów i magazynu Nvidia H100, aby zbudować pionierskie LLM, które może konkurować z ChatGPT.
Ale kiedy szum po cichu osłabł, DeepSeek wkrótce powróci z V4. Omówimy datę premiery DeepSeek v4, co nowego i czego możesz się spodziewać, aby nie przegapić kierunku rozwoju wydarzeń.

Część 1. Co to jest DeepSeek?
DeepSeek to chińskie laboratorium badawcze AI założone w Hangzhou w Chinach, które przez ostatnie kilka lat rzucało wyzwanie gigantom AI, takim jak ChatGPT OpenAI. Tworzy i publikuje duże modele językowe (LLM) na licencjach typu open source, a tym, co przyciąga uwagę, jest to, ile zapewnia przy tak niskich kosztach eksploatacji.
Na początku 2025 roku firma trafiła na pierwsze strony gazet na całym świecie, kiedy wypuściła DeepSeek R1, model rozumowania, który dorównywał o1 OpenAI w testach porównawczych z matematyki i kodowania, a jego wyszkolenie kosztowało podobno około 6 milionów dolarów. Dla porównania oszacowano, że wyszkolenie GPT-4 kosztowało ponad 100 milionów dolarów. Ta wiadomość w ciągu jednego dnia wymazała kapitalizację rynkową firmy NVIDIA o 600 miliardów dolarów.
Pomimo tak wybuchowego początku dynamika DeepSeek AI spadła w ciągu roku. Jego udział w rynku modeli open source spadł z około 50% na początku 2025 r. do poniżej 25% na koniec roku. W ciągu dwunastu miesięcy straciła połowę swojej pozycji rynkowej.
Aktualna wersja i nadchodzący model V4
Ponieważ konkurenci szybko nadrobili zaległości, w grudniu 2025 r. wrócili z dwoma nowymi modelami w ramach DeepSeek V3: DeepSeek-V3.2 i DeepSeek-V3.2-Speciale , oba dostępne bezpłatnie w internecie, aplikacji i interfejsie API.

Obecnie DeepSeek podobno przygotowuje się na DeepSeek V4. Oczekuje się, że usunie słabe punkty poprzednich wersji i obszary, w których DeepSeek wyraźnie pozostawał w tyle za konkurencją multimodalną, takie jak przetwarzanie treści wizualnych , Wyszukiwanie AI ipamięć długokontekstowa .
Część 2. Data premiery DeepSeek V4 i to, co wiemy do tej pory
Choć wielu czekało, data premiery DeepSeek V4 nie została potwierdzona przez samą firmę. Na początku marca na platformie na krótko pojawił się DeepSeek V4 Lite, co wzbudziło jeszcze większe oczekiwania. Niektóre raporty i wczesne dyskusje sugerują, że może pojawić się już w kwietniu 2026 r.
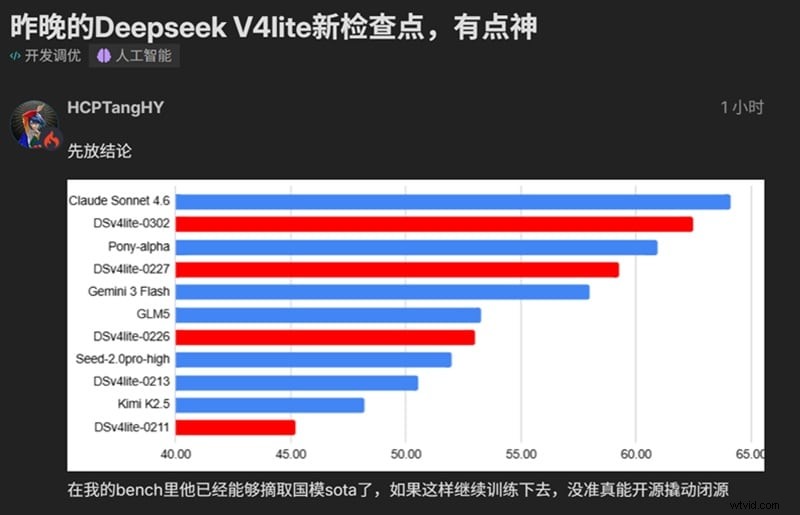
Wyciekły jednak szczegóły dotyczące architektury i wewnętrznych testów porównawczych, które dają wyraźniejszy obraz tego, do czego faktycznie jest budowane V4:
- Kodowanie: Mówi się, że wydajność kodowania DeepSeek V4 osiąga około 81% w teście SWE-bench Verified, w porównaniu z 69% w V3, chociaż niezależna weryfikacja jeszcze się nie odbyła. Dzięki oknu kontekstowemu zawierającemu 1 milion tokenów model może przetwarzać całe bazy kodu w jednym przebiegu.
- Pamięć długoterminowa: V4 opiera się na architekturze pamięci Engram, która oddziela przypominanie faktów od aktywnego rozumowania. Wewnętrzne testy porównawcze mówią o dokładności „igły w stogu siana” na poziomie 97% w skali miliona żetonów.
- Multimodalny: W przeciwieństwie do poprzednich modeli DeepSeek, które udostępniały tylko tekst, V4 integruje tekst, obraz i wideo natywnie podczas treningu przedtreningowego, a nie jako dodatek.
Nawet przy takim rozwoju sytuacji nadal nie ma akcji DeepSeek dostępnych na głównych giełdach, takich jak NASDAQ czy NYSE. DeepSeek to prywatny chiński start-up zajmujący się sztuczną inteligencją, w całości finansowany i będący własnością High-Flyer, chińskiego ilościowego funduszu hedgingowego. Nie jest notowana na giełdzie i nie ogłosiła żadnych planów w tej sprawie.
Oczekiwana cena DeepSeek V4
Oczekuje się, że wersja V4 będzie kosztować 0,30 USD za milion tokenów wejściowych i 0,50 USD za milion tokenów wyjściowych . To nieco więcej niż w wersji 3.2, ale wciąż znacznie poniżej cen GPT i Claude za ich flagowe modele. Platforma czatu DeepSeek AI pozostaje bezpłatna dla użytkowników indywidualnych.
Technologia DeepSeek V4
Za wszystkim, co obiecuje DeepSeek V4, kryje się zestaw ulepszeń architektonicznych, które to umożliwiają.
1. MODEL1 Architektura
Raporty sugerują, że MODEL1 to wewnętrzny kryptonim V4. Łączy w sobie strukturę szkoleniową mHC z przeprojektowaną pamięcią podręczną typu klucz-wartość (KV) za pośrednictwem pamięci Engram. Rezultatem jest model zawierający bilion parametrów który działa na sprzęcie, który kilka lat temu byłby nieodpowiedni dla znacznie mniejszych modeli. Zwiększa wydajność systemu DeepSeek V4, zgłaszając zmniejszenie zużycia pamięci o 40% i 1,8 razy szybsze wnioskowanie dzięki dekodowaniu Sparse FP8.
2. Rzadkie dekodowanie FP8
Wersja 4 domyślnie działa na FP8, który jest lżejszym i szybszym formatem przetwarzania . W przypadku zadań wymagających większej precyzji, takich jak złożone rozumowanie lub matematyka, może automatycznie przełączyć się na FP16. Gdy stawka jest wyższa, możesz szybko wykonywać codzienne zadania, nie rezygnując z dokładności.
3. Moduł pamięci engramów
Jeśli standardowe LLM zwykle przechowują fakty i aktywne rozumowanie w tej samej sieci neuronowej, engram je rozdziela. Rozumowanie pozostaje na GPU w celu szybkiego przetwarzania, podczas gdy faktyczna pamięć jest kompresowana i przywoływana tylko wtedy, gdy jest to potrzebne .
4. Zoptymalizowane połączenia resztkowe mHC
Jednym z głównych powodów, dla których V4 może skalować się bez zwiększania kosztów, jest mHC. Poprawia przepływ informacji między warstwami, przy jedynie około 6,7% dodatkowego narzutu na szkolenie. W rezultacie otrzymujesz bardziej wydajny model bez skoku kosztów, jakiego normalnie można się spodziewać przy tej skali . Ceny API DeepSeek V4 również mogą pozostać konkurencyjne pomimo jego wielkości.
Część 3. Porównanie modeli DeepSeek:R1, V3 i V4
Jak zatem DeepSeek V4 wypada na tle swoich poprzedników? Umieściliśmy te trzy modele obok siebie, aby ułatwić Ci sprawdzenie, co faktycznie zmieniło się w poszczególnych generacjach.
| R1 | V3 | V4 | ||
| Parametry | 671B łącznie, 37B aktywnych | 671B łącznie, 37B aktywnych | 1 bilion (szacunkowo) | |
| Okno kontekstowe | 128 tys. tokenów | 128 tys. tokenów | 1 milion tokenów | |
| Wzorce kodowania | Porównywalne z OpenAI o1 | 69% zweryfikowanych w SWE-bench | 81% zweryfikowanych w SWE-bench (szacunkowo) | |
| Funkcje rozumowania | Czysty model rozumowania oparty na łańcuchu myślowym | Hybrydowy; rozumowanie wywodzące się z R1 | Hybrydowy; głębsze rozumowanie w długim kontekście za pomocą Engramu | |
| Multimodalny | Tylko tekst | Tylko tekst | Tekst, obraz, wideo (natywny) | |
| Ceny API (dane wejściowe) | Tokeny o wartości 0,55 USD/M | Tokeny o wartości 0,14–0,28 USD/mln | Tokeny o wartości 0,30 USD/M |
 Bezpieczne pobieranie
Bezpieczne pobieranie| DeepSeek V4 | GPT-5.4 | Gemini 3.1 Pro | Claude Opus 4.6 | |
| Open Source | ||||
| Umiejętności rozumowania | Silny dzięki pamięci Engram, która poprawia rozumowanie w długim kontekście | 92,8% GPQA | 94,3% GPQA | 91,3% GPQA |
| Kodowanie agentowe | ~81% zweryfikowanych w SWE-bench (szacunkowo) | 80% weryfikacji w SWE-bench | 80,6% zweryfikowanych w SWE-bench | 80,8% zweryfikowanych w SWE-bench |
| Okno kontekstowe | 1 milion tokenów | 272 tys. tokenów (standardowo); 1 milion tokenów (Kodeks) | 1 milion tokenów | 1 milion tokenów |
| Wejście (na 1 milion tokenów) | 0,3 USD | 2,5 USD | 2 USD | 5 USD |
| Wyjście (na 1 milion tokenów) | 0,5 USD | 15 USD | 12 USD | 25 USD |
| Najlepsze dla | Obciążenia API wrażliwe na koszty, kodowanie, elastyczność open source | Wszechstronność, obsługa komputera, praca oparta na wiedzy | Rozumowanie na poziomie doktoratu, badania, stosunek ceny do wydajności | Złożone kodowanie, agentyczne przepływy pracy, przedsiębiorstwo |
| Ekosystem | Open-source, możliwość samodzielnego hostowania | Największe integracje z firmami zewnętrznymi | Głęboka integracja z Google Workspace | Zaawansowane narzędzia programistyczne (kursor, kod Claude) |
