Konwersja mowy na tekst nigdy nie była łatwiejsza dzięki modelom zamiany mowy na tekst w Hugging Face. Niezależnie od tego, czy transkrypujesz wywiady, generujesz napisy, czy tworzysz aplikacje oparte na sztucznej inteligencji, Hugging Face zapewnia najnowocześniejsze rozpoznawanie mowy oparte na zaawansowanych modelach uczenia maszynowego. Najlepsza część? Można go w dużym stopniu dostosowywać, co pozwala na precyzyjne dostrojenie modeli w celu uzyskania większej dokładności i wydajności w zależności od konkretnych potrzeb.
W tym przewodniku przeprowadzimy Cię przez proces konfigurowania i używania interfejsu API Hugging Face zamieniającego mowę na tekst , poznaj opcje dostosowywania i omów praktyczne przypadki użycia. Ale co, jeśli potrzebujesz prostszej alternatywy? Nie martw się — wprowadzimy także łatwe w obsłudze narzędzie do zamiany mowy na tekst, które bez trudu wykona to zadanie. Niezależnie od tego, czy jesteś programistą, twórcą treści czy profesjonalistą biznesowym, ten przewodnik pomoże Ci znaleźć najlepsze rozwiązanie do zamiany mowy na tekst dla Twojego przepływu pracy. Czytaj dalej.
W tym artykule
- Jak działa funkcja przytulania mowy do tekstu
- Konfigurowanie mowy obejmującej twarz na tekst
- Łatwiejsza alternatywa:automatyczna zamiana mowy na tekst za pomocą Filmory
- Które narzędzie jest najlepsze
Część 1:Jak działa przytulanie mowy do tekstu
Hugging Face Speech-to-Text to świetna funkcja dostępna w bibliotece Hugging Face Transformers, która umożliwia przekształcanie wypowiadanych słów w tekst pisany przy użyciu wstępnie wyszkolonych modeli. Do transkrypcji mowy wykorzystuje zaawansowaną technologię automatycznego rozpoznawania mowy (ASR). Dzięki architekturze opartej na transformatorach, takiej jak Wav2Vec2, system przetwarza dane audio i konwertuje je na tekst. I robi to z dużą dokładnością.
Jedna z rzeczy, która umożliwia zamianę mowy na tekst w uścisku twarzy Wyróżnia się integracja z potokiem, która sprawia, że jest to niezwykle łatwe dla programistów. Za pomocą zaledwie kilku linii kodu możesz przetwarzać pliki audio i uzyskać transkrypcje tekstowe. Zawiera także wstępnie wytrenowane modele dla wielu języków i scenariuszy mowy, dzięki czemu można je dostosować do wielu przypadków użycia.
Proces zamiany mowy na tekst przebiega krok po kroku, aby zapewnić dokładną transkrypcję:
- Wejście audio:udostępniasz plik audio do przetworzenia.
- Ekstrakcja cech:system wyodrębnia cechy mowy i banki filtrów log-mel. Pomaga to analizować wzorce dźwiękowe.
- Wnioskowanie o modelu:wstępnie wytrenowany model transformatora przetwarza funkcje i generuje tokeny tekstowe reprezentujące wypowiadane słowa.
- Wyjście tekstowe:model konwertuje te tokeny na transkrypcję tekstową.
Modele zamiany mowy na tekst Hugging Face, w szczególności SeamlessM4T-v2, poprawiają wydajność poprzez wdrożenie struktury podwójnej sekwencji do sekwencji (seq2seq). Posiada osobne kodery mowy i tekstu oraz wokoder HiFi-GAN, który poprawia jakość generowanego głosu. Jest to przydatne narzędzie do rozpoznawania i automatyzacji mowy, zawierające aplikacje obejmujące wirtualnych asystentów, napisy na żywo, usługi transkrypcji i wyszukiwanie głosowe.
Część 2:Konfigurowanie mowy obejmującej twarz na tekst
Poniżej znajduje się przewodnik krok po kroku dotyczący konfiguracji umożliwiającej zamianę tekstu na mowę obejmującą twarzą:
Krok 1:Utwórz konto z uściskiem twarzy

Pierwszym, czego potrzebujesz, jest konto na Hugging Face. Utworzenie konta zapewnia dostęp do wstępnie wyszkolonych modeli i interfejsów API. Jeśli nie masz jeszcze konta;
- Przejdź do strony z przytulaniem twarzy
- Kliknij Zarejestruj się
- Wprowadź swoje dane i utwórz konto
- Po zalogowaniu przejdź do Ustawień profilu
- Znajdź tokeny dostępu i utwórz nowy token (wybierz „Zapis” jako poziom uprawnień)
Ten token pomoże Ci połączyć się z Hugging Face za pomocą Twojego kodu.
Krok 2:zainstaluj wymagane biblioteki
Następną rzeczą, którą musisz zrobić, to zainstalować wszystkie potrzebne biblioteki. Aby to zrobić, otwórz terminal lub wiersz poleceń i wpisz:
pip zainstaluj zestawy danych Transformers plik dźwiękowy Torchaudio Librosa
Transformers służy do ładowania modeli Hugging Face, torchaudio pomaga przetwarzać dane audio, podczas gdy librosa i plik dźwiękowy pomagają ładować i modyfikować pliki audio.
Krok 3:Załaduj model
Po zainstalowaniu wszystkich wymaganych bibliotek następną rzeczą, którą musisz zrobić, to załadować model zamiany mowy na tekst. Możesz użyć Wav2Vec2, ponieważ jest to jeden z najlepiej wytrenowanych modeli rozpoznawania mowy.
z importu transformatorów Wav2Vec2ForCTC, Wav2Vec2Processor
importuj latarkę
# Załaduj model i procesor
model_name ="facebook/wav2vec2-large-960h"
procesor =Wav2Vec2Processor.from_pretrained(nazwa_modelu)
model =Wav2Vec2ForCTC.from_pretrained(nazwa_modelu)
Krok 4:Konwertuj dźwięk na tekst
Musisz przygotować plik audio, aby model mógł go zrozumieć. Aby to osiągnąć, musisz załadować dźwięk do swojego oprogramowania. Następnie upewnij się, że jest on we właściwym formacie, aby model mógł go odpowiednio przetworzyć. Przepuścisz go przez model, aby przekształcić mowę w tekst.
importuj librosę
#Załaduj plik audio i przekonwertuj go na 16 kHz
def ładowanie_audio(ścieżka_pliku):
audio, sr =librosa.load(file_path, sr=16000)
zwrócić dźwięk
audio_file ="przykład.wav"
wejście_audio =ładowanie_audio(plik_audio)
Przetwórz sygnał wejściowy audio, aby model mógł go odczytać
input_values =procesor(audio_input, return_tensors="pt", sampling_rate=16000).input_values

Uwaga:w przypadku większych projektów Hugging Face oferuje punkt końcowy API, który umożliwia zdalne przetwarzanie mowy bez konieczności zarządzania modelem na własnym urządzeniu. Po prostu załóż konto Hugging Face, uzyskaj klucz API i wysyłaj pliki audio za pomocą prostego żądania API.
Jak dostosować modele zamiany mowy na tekst
Jeśli chcesz, aby model przytulania twarzy zamieniający mowę na tekst działał lepiej, musisz go dopracować. Podstawowy model jest dobry, ale może nie rozumieć pewnych akcentów, szumów tła lub specjalnych słów. Uczenie go przy użyciu własnych danych pomaga mu się uczyć i doskonalić, dzięki czemu jest znacznie dokładniejszy w stosunku do Twoich potrzeb. Oto jak możesz dostroić model:
- Dostosuj za pomocą niestandardowych danych:trenuj model przy użyciu własnych zestawów danych audio i transkrypcji, aby poprawić rozpoznawanie określonych akcentów lub terminów branżowych.
- Dostosuj ustawienia wnioskowania:zmodyfikuj parametry, takie jak temperatura i wyszukiwanie wiązki, aby poprawić dokładność.
- Dodaj niestandardowe słownictwo:naucz model nowych słów i zwrotów istotnych dla Twojej domeny.
Personalizacja sprawia, że model jest bardziej precyzyjny i niezawodny dla Twoich konkretnych potrzeb. Jeśli jednak wolisz prostsze rozwiązanie, zapoznaj się z następną sekcją, w której znajdziesz łatwą alternatywę dla zamiany mowy na tekst!
Część 3:Łatwiejsza alternatywa:automatyczna zamiana mowy na tekst za pomocą Filmory
Zamiana mowy na tekst z przytulaniem twarzy wydaje się zbyt skomplikowana i wymaga umiejętności technicznych, takich jak kodowanie. Istnieje jednak łatwiejsza alternatywa:Wondershare Filmora to znacznie prostsze podejście do konwersji mowy na tekst. Filmora to popularne oprogramowanie do edycji wideo wyposażone w narzędzie do zamiany mowy na tekst, które automatycznie transkrybuje dźwięk za pomocą kilku kliknięć.
- Filmora upraszcza wszystko dla Ciebie. Nie potrzebujesz więc umiejętności programowania ani skomplikowanych konfiguracji.
- Może transkrybować mowę wideo na tekst z dokładnością do 99%. Dlatego twórcy treści, studenci, a nawet profesjonaliści biznesowi mogą go używać do szybkiego i dokładnego generowania tekstu z dźwięku.
- Obsługuje ponad 45 języków i dobrze sprawdza się w przypadku napisów do filmów, notatek głosowych i wywiadów.
- Jest wyposażony w automatyczne tłumaczenie napisów dla treści wielojęzycznych
- Możesz generować dostosowywalne animowane napisy, aby zwiększyć zaangażowanie
- Ponadto wbudowana funkcja zamiany mowy na tekst firmy Filmora bardzo szybko przetwarza dane audio i oszczędza czas użytkownika. Szybkość i oszczędność czasu sprawiają, że jest to najlepsza alternatywa.
Część 4:Jak korzystać z funkcji zamiany mowy na tekst Filmora
Filmora sprawia, że konwersja mowy na tekst jest bardzo prosta. Nie ma potrzeby tworzenia kodu ani konfigurowania niczego trudnego.
Postępuj zgodnie z tymi prostymi instrukcjami, aby błyskawicznie uzyskać transkrypcję, korzystając z funkcji zamiany mowy na tekst na komputerze:
Krok 1:Zaimportuj swoje audio lub wideo
Otwórz Filmorę i dodaj plik audio lub wideo. Można to zrobić po prostu przeciągając i upuszczając go na oś czasu. Dzięki temu będzie Ci łatwiej. Gdy plik będzie już na swoim miejscu, możesz kontynuować.
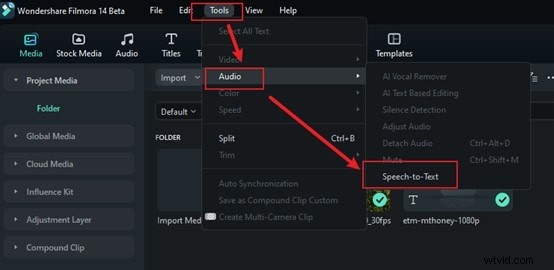
Krok 2:Wybierz opcję zamiany mowy na tekst
Przejdź do opcji Narzędzia na górnym pasku menu i kliknij ją. Wybierz opcję Audio, a następnie Tekst na mowę, aby automatycznie analizować dźwięk. Nie musisz dostosowywać ustawień ani wykonywać żadnych dodatkowych czynności, ponieważ wszystko zrobi za Ciebie.
Krok 3:Wybierz swój język
Filmora obsługuje wiele języków, więc wybierz ten, który pasuje do Twojego dźwięku. Ten krok jest ważny, ponieważ wybór odpowiedniego języka pomaga Filmorze w dokładnej transkrypcji Twojej wypowiedzi. Jeśli to pominiesz, możesz uzyskać nieprawidłowe wyniki.
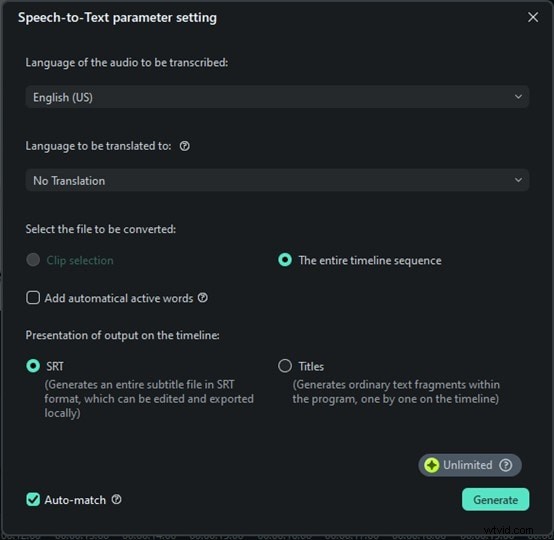
Krok 4:Rozpocznij transkrypcję i zapisz
Teraz wystarczy kliknąć Generuj, a Filmora rozpocznie transkrypcję Twojej wypowiedzi. Ta część jest naprawdę szybka. W ciągu kilku sekund zobaczysz, że wypowiedziane słowa pojawią się jako tekst. Bez czekania godzinami, bez skomplikowanej konfiguracji, po prostu natychmiastowe rezultaty. Kliknij plik tekstowy, wybierz opcję Eksportuj transkrypcję pliku napisów, aby go zapisać i dodać jako napisy do swojego filmu.
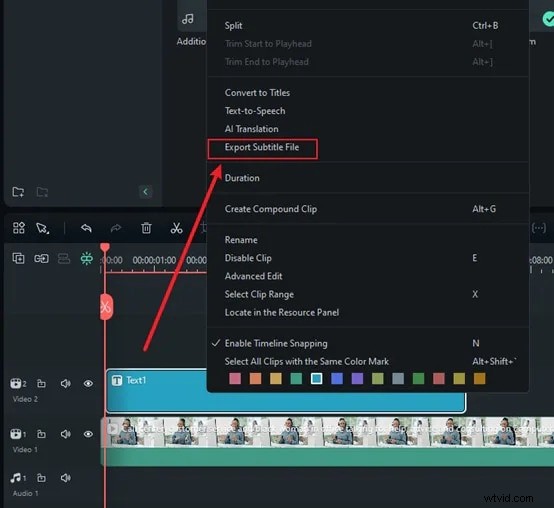
Jeśli chcesz przekonwertować mowę wideo na napisy tekstowe, Filmora oferuje również funkcję napisów AI w swojej aplikacji mobilnej. Umożliwia wygenerowanie napisów tekstowych na urządzeniu mobilnym w mniej niż minutę
Krok 1:Pobierz aplikację Filmora ze sklepu Google Play (Android) lub App Store (iPhone). Można go również pobrać z oficjalnej strony internetowej. Po zainstalowaniu otwórz aplikację i dotknij Nowy projekt.
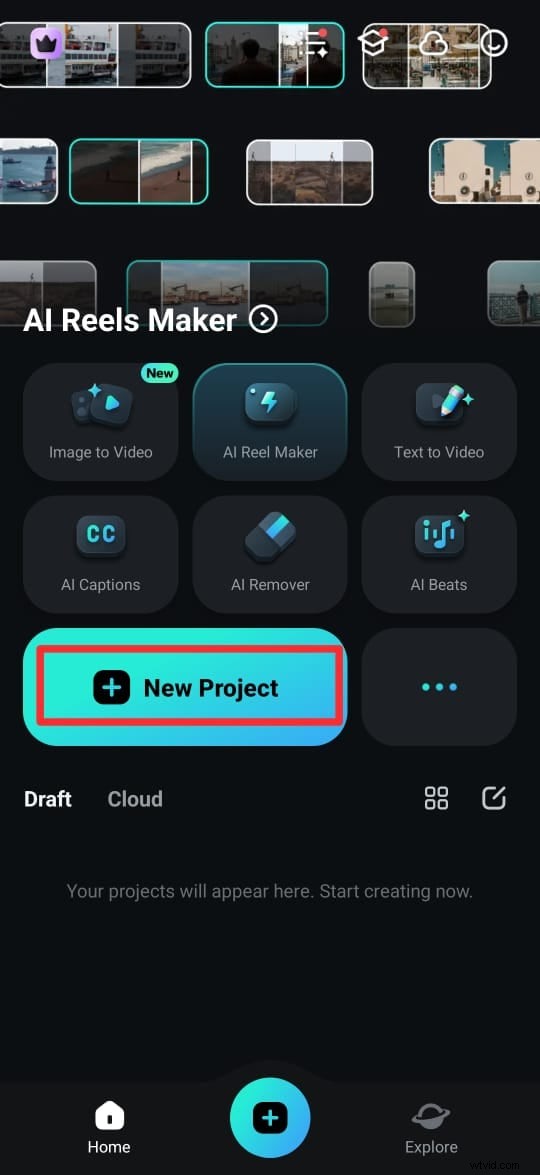
Krok 2. Wybierz film ze swojej biblioteki multimediów i dotknij Importuj, aby dodać go do swojego obszaru roboczego.

Krok 3:W dolnym menu kliknij Tekst (oznaczony ikoną T) i wybierz Napisy AI.
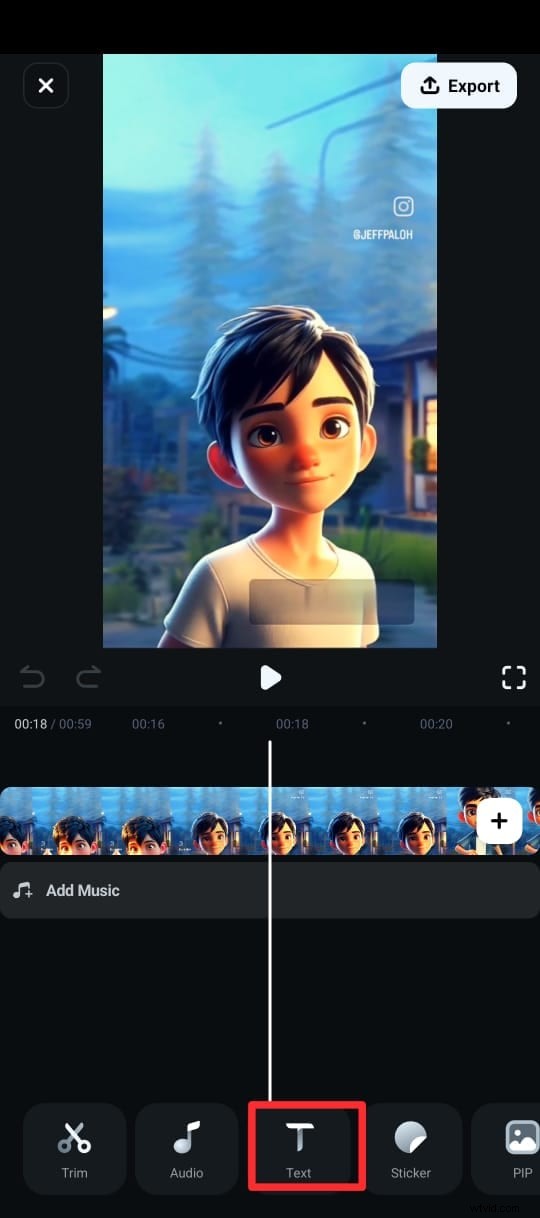
Krok 4:Na następnym ekranie wybierz język, włącz opcję Wykrywanie głośników i dotknij Dodaj napisy, aby wygenerować tekst na podstawie mowy filmu.
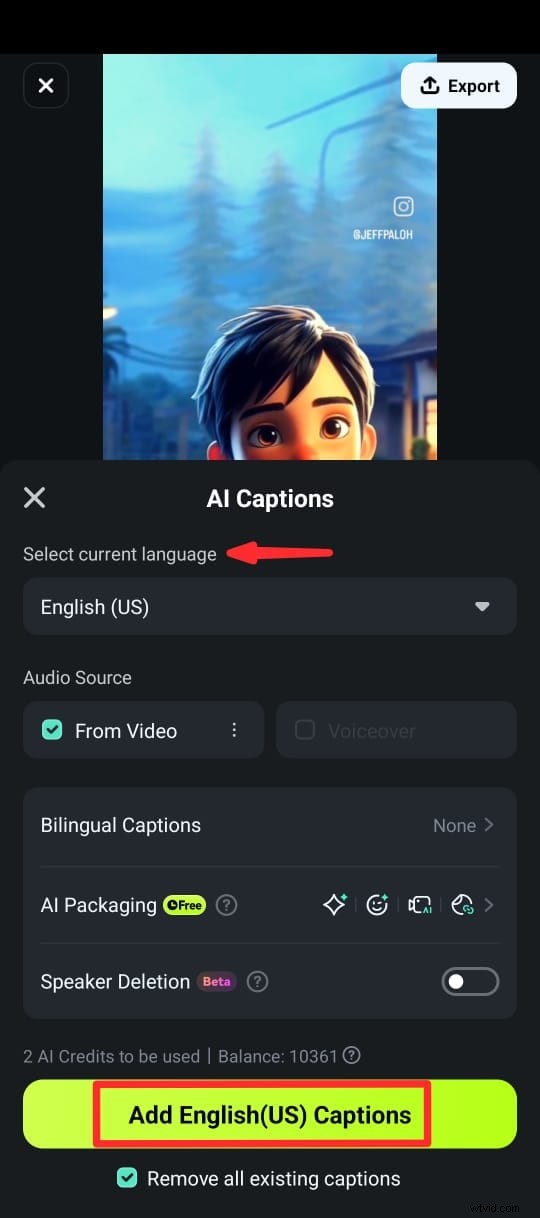
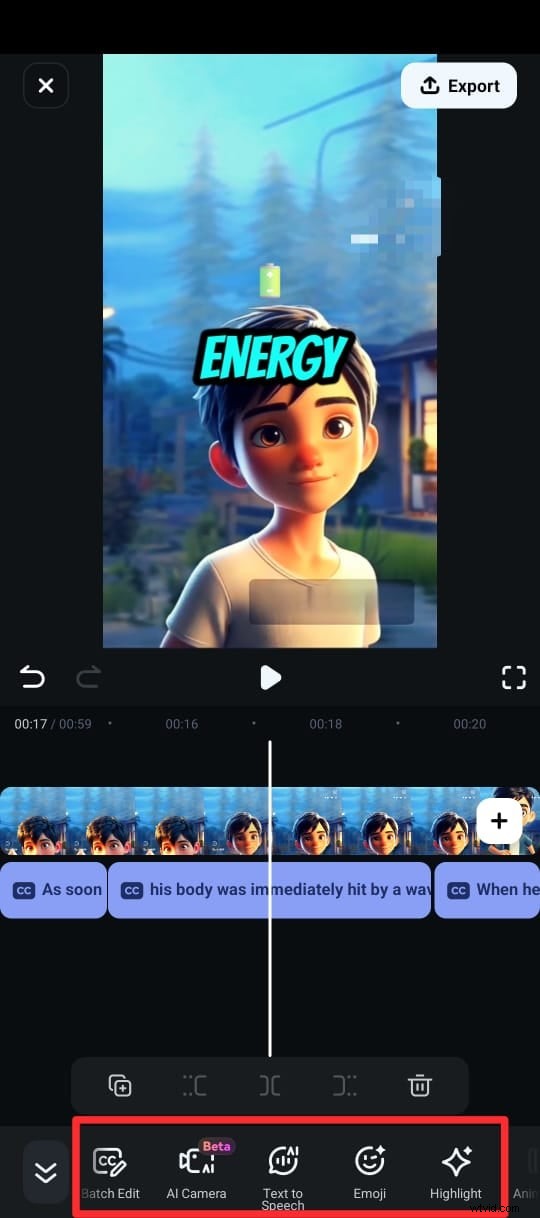
Krok 5:Po wygenerowaniu podpisów możesz dostosować tekst, używając różnych szablonów tekstu, emoji i czcionek. Możesz także edytować tekst w klipie na osi czasu, wybierając opcję Edytuj mowę z pakietu edycyjnego.
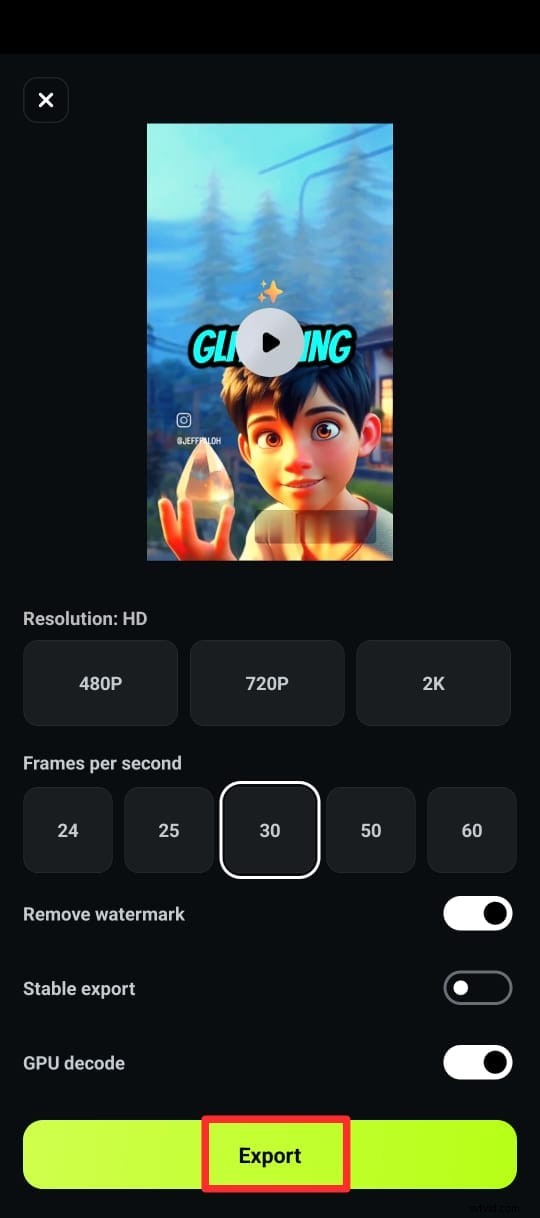
Krok 6:Wyeksportuj swój film z napisami w żądanym formacie.
Część 5. Które narzędzie jest najlepsze?
Wybór pomiędzy Hugging Face a Filmora zależy od Twoich konkretnych potrzeb i poziomu wiedzy technicznej. Każde narzędzie służy innemu celowi, więc sprawdźmy, które z nich będzie dla Ciebie odpowiednie, na podstawie różnych scenariuszy.
- Jeśli potrzebujesz zaawansowanej personalizacji i kontroli opartej na sztucznej inteligencji, lepszym wyborem będzie zamiana mowy na tekst z przytuloną twarzą. Jest idealny dla programistów, badaczy i profesjonalistów, którzy chcą szkolić modele, dostrajać parametry i pracować z dużymi zbiorami danych. Wymaga jednak wiedzy na temat kodowania i czasu na konfigurację, co czyni go mniej odpowiednim dla początkujących lub osób poszukujących szybkiego rozwiązania.
- Z drugiej strony, jeśli potrzebujesz szybkiego i dokładnego narzędzia do transkrypcji bez żadnych konfiguracji technicznych, najlepszym wyborem będzie Filmora. Jest przeznaczony dla twórców treści, studentów i profesjonalistów, którzy potrzebują prostego rozwiązania obsługiwanego jednym kliknięciem.
- Użyj Filmory, jeśli dodajesz napisy do filmów, transkrybujesz wykłady lub konwertujesz mowę na tekst na potrzeby raportów.
- Dla osób pracujących w niszowych dziedzinach, które wymagają rozpoznawania mowy specyficznej dla danej domeny, Hugging Face umożliwia przeszkolenie modelu w zakresie terminologii specyficznej dla branży. Zapewnia to większą dokładność w przypadku złożonego żargonu, ale ponownie wymaga wysiłku i wiedzy technicznej.
- Tymczasem, jeśli Twoim głównym celem jest transkrypcja treści wideo, Filmora jest wygodniejszą opcją, ponieważ szybko konwertuje mowę na tekst, co czyni ją idealną dla YouTuberów, podcasterów i twórców mediów społecznościowych.
Podsumowując, jeśli kochasz kodowanie i chcesz pełnej kontroli i dostosowywania, wybierz funkcję zamiany tekstu na mowę w huggingface. Jeśli jednak potrzebujesz łatwego i natychmiastowego narzędzia do transkrypcji, Filmora jest idealnym wyborem. Wybierz ten, który najlepiej pasuje do Twojego przepływu pracy i poziomu umiejętności.
Wniosek
Konwersja mowy na tekst nie musi być skomplikowana. Przytulanie tekstu na mowę to potężne narzędzie, ale wymaga kodowania i konfiguracji, co jest fajne dla programistów. Jeśli jednak chcesz czegoś szybkiego i łatwego, Filmora jest najlepszą alternatywą. Za pomocą kilku kliknięć możesz bez wysiłku transkrybować dźwięk; bez kodowania i bez stresu. Po co spędzać godziny na skomplikowanych konfiguracjach? Wypróbuj funkcję zamiany mowy na tekst firmy Filmora już dziś i zamień dźwięk na tekst w ciągu kilku sekund