Najważniejsze wnioski
- Seedance2.0 to flagowy model wideo AI firmy ByteDance, zaprojektowany dla twórców wymagających precyzyjnej kontroli nad spójnością, ruchem i dźwiękiem.
- Jego mocną stroną jest generowanie multimodalne, umożliwiające twórcom łączenie tekstów, obrazów, plików wideo i plików audio w jednym, usprawnionym przepływie pracy.
- Podstawowe funkcje obejmują oznaczanie zasobów w oparciu o role, zwiększoną spójność znaków, ruch oparty na referencjach, natywne generowanie dźwięku i synchronizację uwzględniającą rytm.
- W porównaniu z innymi wiodącymi modelami, Seedance2.0 wyróżnia się, gdy wierność odniesienia i wyrównanie audiowizualne przewyższają maksymalną rozdzielczość.
- Dzięki InVideo twórcy mogą płynnie przechodzić od generacji do edycji i eksportu, utrzymując całą pętlę produkcyjną w jednym interfejsie.
Narzędzia wideo oparte na sztucznej inteligencji wykraczają poza generowanie krótkich, efektownych wizualnie klipów. Tym, co obecnie wyróżnia te naprawdę wartościowe, jest poziom kontroli, jaki zapewniają. Twórcy potrzebują czegoś więcej niż tylko estetyki filmowej; wymagają systemu, który podąża za odniesieniami, zachowuje spójność charakteru, reaguje na sygnały ruchu i płynnie integruje się z rzeczywistym przepływem pracy w produkcji.
Seedance2.0 podejmuje to wyzwanie. Poniżej omawiamy, co to jest, jakie funkcje mają największe znaczenie, jak wypada na tle innych liderów branży i praktyczne sposoby wdrożenia go w formacie InVideo.
Co to jest Seedance2.0?

10 lutego 2026 r. zespół badawczy ByteDance Seed uruchomił Seedance2.0, model zapewniający prawdziwą kontrolę reżyserską nad klipami generowanymi przez sztuczną inteligencję. Zbudowany w oparciu o ujednolicony multimodalny system generowania audio-wideo, akceptuje tekst, obrazy, dźwięk i wideo jako dane wejściowe, umożliwiając zaawansowaną obsługę referencji i przepływy pracy związane z edycją po generacji.
Seedance2.0 tworzy klipy trwające od 4 do 15 sekund, obsługuje rozdzielczość do 1080p i obsługuje wiele współczynników proporcji — w tym 16:9, 9:16, 4:3, 3:4, 21:9 i 1:1.
Prawdziwą zmianą jest sposób, w jaki model przetwarza dane wejściowe. Zamiast polegać wyłącznie na podpowiedziach tekstowych, twórcy mogą bezpośrednio podawać kierunek wizualny, wskazówki dotyczące ruchu i odniesienia dźwiękowe, przekształcając Seedance2.0 z jednorazowego generatora w kontrolowany system kreatywny.
Funkcje Seedance2.0, które są najważniejsze dla twórców
1. Podpowiadanie multimodalne — jak kierowanie załogą
Multimodalny system wejściowy Seedance2.0 jest jego podstawową przewagą konkurencyjną. Twórcy mogą łączyć tekst, obrazy, wideo i dźwięk w ramach jednej generacji.
Akceptuje do:
- 9 odniesień do obrazów
- 3 referencje wideo
- 3 referencje audio
Do każdego odniesienia można przypisać rolę, która pomaga modelowi zrozumieć, co dany zasób ma kontrolować:
- Zdjęcie produktu definiuje temat.
- Klip ruchomy steruje zachowaniem kamery.
- Plik audio kształtuje tempo lub rytm.
Rezultat bardziej przypomina reżyserowanie niż zgadywanie, dzięki czemu Seedance2.0 idealnie nadaje się do filmów AI, filmów marek, promocji i wszelkich przepływów pracy, w których spójność jest równie ważna jak styl.
2. Większa spójność znaków
Utrzymanie tożsamości w różnych klatkach pozostaje główną przeszkodą w generowaniu wideo AI. Seedance2.0 zaprojektowano tak, aby zachować twarze, ubrania, akcesoria i subtelne szczegóły w całym klipie, umożliwiając tworzenie scen opartych na opowieściach, treści związanych z marką postaci i powtarzalnych formatów kreatywnych.
Problemy z ciągłością wizualną często powstrzymują wideo AI przed wyjściem poza klipy eksperymentalne; Seedance2.0 rozwiązuje ten problem bezpośrednio.
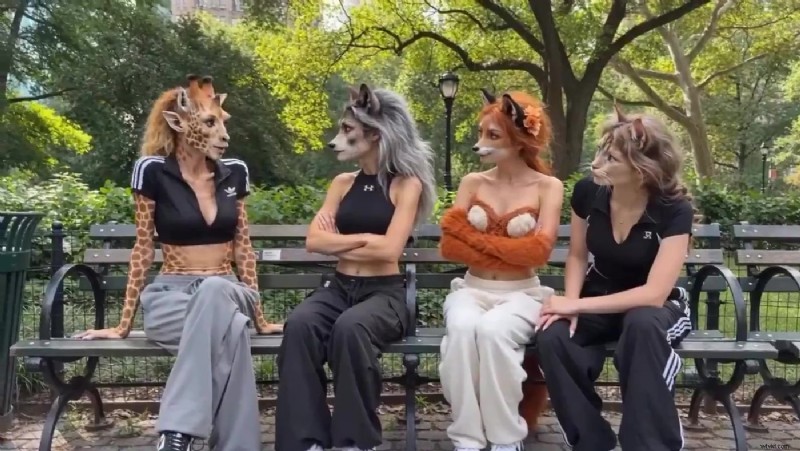

Źródło
3. Replikacja ruchu oparta na odniesieniach
Prześlij klip z żądaną ścieżką kamery lub stylem ruchu i użyj go jako odniesienia dla nowych pokoleń. Jest to nieocenione w przypadku scen pełnych akcji, filmów prezentacyjnych, ujęć orbitalnych i sekwencji filmowych, w których pomysł definiuje ruch.
4. Natywne generowanie dźwięku i synchronizacja rytmu
Dźwięk i obraz są generowane razem, co eliminuje potrzebę poprawiania dźwięku w postprodukcji. Model może od samego początku dopasować efekt wizualny do dialogów, efektów dźwiękowych i rytmu, co jest niezbędne w przypadku edycji opartych na muzyce, promocji, zwiastunów lub krótkich treści związanych z marką.
Synchronizacja uwzględniająca rytm oznacza mniej późniejszych ręcznych poprawek i lepszy pierwszy wynik w przypadku treści zorientowanych na wydajność.
5. Procesy edycji i rozszerzania wideo
Seedance2.0 obsługuje iteracyjne przepływy pracy. Twórcy mogą selektywnie edytować istniejące klipy zamiast całkowicie je regenerować, a także rozszerzać krótsze klipy na dłuższe, zachowując jednocześnie styl i tożsamość wizualną. Ma to kluczowe znaczenie, ponieważ większość twórców raczej iteruje niż dąży do perfekcji za jednym razem.
Czym Seedance 2.0 różni się od wcześniejszych modeli wideo AI
Poprzednie modele wideo AI tworzyły atrakcyjne wizualnie klipy w izolacji, ale często brakowało im ciągłości, kierunku i powtarzalności. Seedance2.0 wypełnia tę lukę poprzez:
- Praca z referencjami w celu utrzymania tożsamości wizualnej przy zmianie kamery.
- Zachowanie wierności w pełnych ruchu zdjęciach produktów.
- Integracja dźwięku i ruchu od samego początku, ograniczająca ręczną synchronizację.
Jest to model bardziej dostosowany do potrzeb produkcyjnych, oferujący głębszą kontrolę multimodalną i ściślejsze dopasowanie audiowizualne. Prawdziwa wartość polega na zmniejszeniu tarcia między pomysłem a gotowym produktem.
Seedance2.0 kontra Kling3.0 kontra VEO3.1
Każdy model jest skierowany do nieco innej niszy. Seedance2.0 sprawdza się tam, gdzie najważniejsza jest kontrola oparta na referencjach, prowadzenie ruchu i przepływ pracy uwzględniający rytm. Kling3.0 wyróżnia się wydajnością w wysokiej rozdzielczości, szczególnie w przypadku dostarczania 4K lub systemów znaków powtarzalnych. VEO3.1 najlepiej nadaje się do przedłużania krótkich klipów w dłuższe sekwencje.
| Możliwości | Seedance2.0 | Kling3.0 | VEO3.1 |
|---|---|---|---|
| Maksymalny czas trwania klipu | 15 sekund | 15 sekund | 8 sekund, z możliwością przedłużenia |
| Maksymalna rozdzielczość | 1080p | Do 4K | Do 4K |
| Natywny dźwięk | Tak, ten sam przebieg renderowania | Tak, zależy od przepływu pracy | Tylko model standardowy |
| Wejścia referencyjne | Do 9 obrazów, 3 filmów, 3 plików audio i tekstu | Obrazy i odniesienia do filmów oraz tekst | Maksymalnie 3 obrazy i tekst |
| Kontrola aktywów | @wzmianki z przypisaniem roli | Elementy do blokowania znaków | Odniesienia dotyczące składników |
| Replikacja ruchu | Tak, wyodrębnia i stosuje podpisy ruchu | Bardziej ograniczone | Kontrola rozpoczęcia i zakończenia ramki |
| Synchronizacja rytmu | Tak, natywny | Nie | Nie |
| Generowanie wielu strzałów | Tak, wiele scen w jednym wyjściu | Tak, do 6 cięć na klip | Poprzez rozszerzenie sceny |
| Zamiana elementów | Tak, nieniszczące | Tak, za pomocą narzędzi do edycji | Ograniczona |
| Proporcje | 16:9, 9:16, 4:3, 3:4, 21:9, 1:1 | Wiele, w tym 16:9 i 9:16 | 16:9, 9:16 |