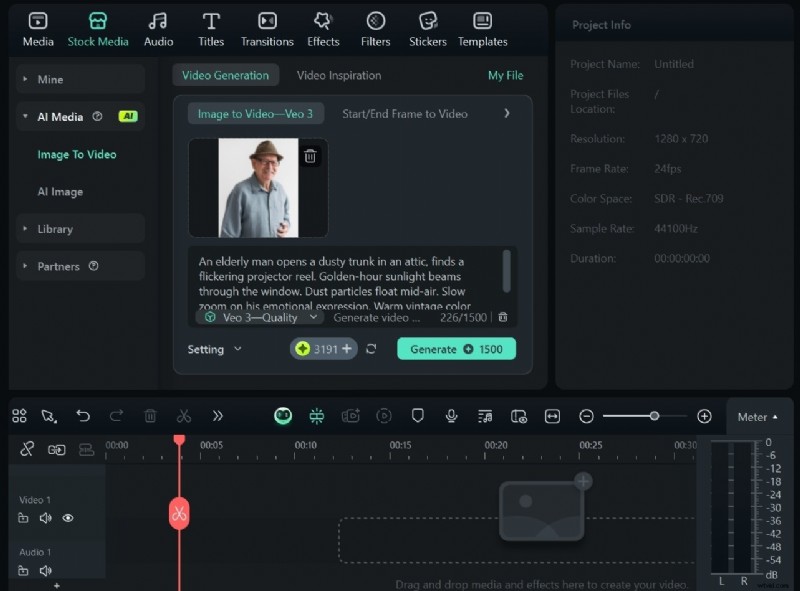
Wraz z wprowadzeniem Veo 3 firma Google oficjalnie rozpoczęła generowanie wideo AI. Google Veo 3 to nowy generator wideo AI, który przekształca podpowiedzi tekstowe w krótkie filmy o wysokiej jakości. Został stworzony dla twórców, nauczycieli i marketerów i oferuje zaawansowane renderowanie scen, płynny ruch i kontrolę wielu ujęć, a wszystko to dzięki najnowszemu modelowi generatywnemu Google.
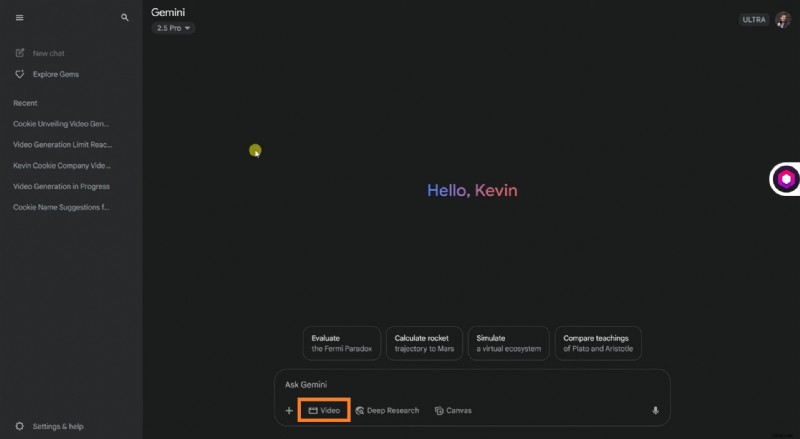
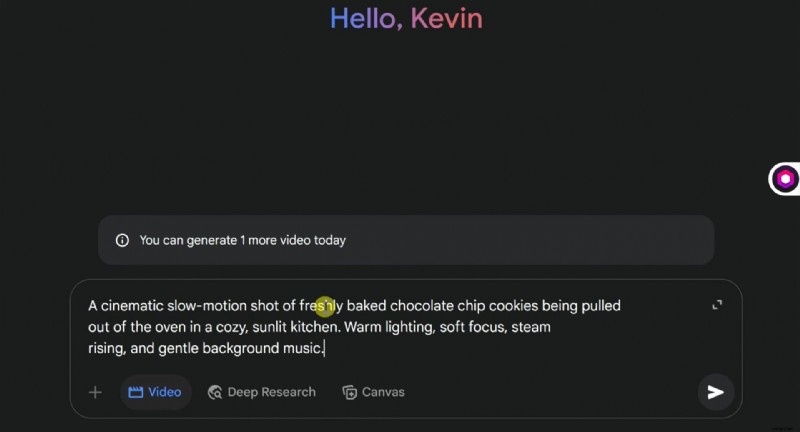
W tym przewodniku opisano, jak skutecznie uzyskać dostęp do Google Veo 3 AI i efektywnie z niego korzystać. Tutaj poznasz proces krok po kroku, zobaczysz, w jakich scenariuszach najlepiej pasuje, np. w marketingu czy edukacji, i zrozumiesz jego obecne ograniczenia. Jeśli Veo 3 nie jest jeszcze dla Ciebie dostępny, pokażemy Ci również, jak uzyskać podobne rezultaty, korzystając z jeszcze bardziej zaawansowanego narzędzia. Czytaj dalej, aby dowiedzieć się więcej.

W tym artykule
- Krótki przegląd modelu AI Google Veo 3
- Jak uzyskać dostęp do Google Veo 3 i z niego korzystać
- Przewodnik krok po kroku dotyczący korzystania z nowego generatora wideo AI firmy Google
- Generuj i edytuj filmy za pomocą tego zaawansowanego edytora wideo zintegrowanego z Veo
Krótki przegląd modelu AI Google Veo 3
Google Veo 3 oznacza ambitne wejście technologicznego giganta na arenę generatywnego wideo. W przeciwieństwie do podstawowych narzędzi do przetwarzania tekstu na wideo, Veo 3 wykorzystuje najnowocześniejsze badania Google DeepMind do tworzenia kinowych filmów w wysokiej rozdzielczości (1080p+) na podstawie podpowiedzi tekstowych, w tym podpowiedzi Veo 3, takich jak uporządkowane opisy scen, ruchy kamery, style wizualne i tony emocjonalne – obsługując zmienną długość ujęć i złożone przejścia scen.

Podstawowe funkcje Google Veo 3
- Generowanie wideo o wysokiej jakości
- Generuje filmy w rozdzielczości 1080p lub wyższej przy kinowej liczbie klatek na sekundę (24–60 klatek na sekundę).
- Obsługuje dłuższe czasy trwania (potencjalnie ponad 60 sekund) przy zachowaniu spójności czasowej.
- Synchronizacja audiowizualna
- Synchronizacja ust:realistyczne ruchy ust dopasowane do mowy (np. w przypadku wirtualnych awatarów).
- Efekty dźwiękowe:dynamiczne dopasowanie dźwięku (np. kroków, eksplozji) do efektów wizualnych.
- Wejście wielomodalne
- Akceptuje podpowiedzi tekstowe, dźwiękowe i graficzne (np. „tańczący kot” + ścieżka muzyczna).
- Dokładna kontrola nad kątami kamery, oświetleniem i stylami.
- Rozumienie sceny 3D
- Symuluje fizykę (grawitację, kolizje) i renderowanie z uwzględnieniem głębi.
- Zachowuje trwałość obiektu (bez „zakłóceń” w dłuższych klipach).
- Efektywna edycja
- Modyfikuje istniejące filmy za pomocą poleceń tekstowych/głosowych (np. „zmień tło na Marsa”).
Kluczowe innowacje techniczne
| Innowacja | Jak to działa | Dlaczego jest to ważne | ||
| Transformator dyfuzyjny (DiT) | Łączy modele dyfuzyjne z transformatorami w celu uzyskania skalowalnego wideo o wysokiej rozdzielczości. | Umożliwia dłuższe i bardziej spójne filmy. | ||
| Sieć czasoprzestrzenna U-Net | Przetwarza wideo w blokach przestrzennych i czasowych, aby zredukować migotanie. | Płynniejsze przejścia klatek. | ||
| Krosmodalne, kontrastowe uczenie się | Wyrównuje dźwięk, tekst i wideo we współdzielonej przestrzeni ukrytej (np. CLIP). | Dokładna synchronizacja audiowizualna. | ||
| Renderowanie neuronowe | Zawiera dyfuzję obsługującą 3D (podobnie jak NeRF). | Realistyczne efekty oświetlenia/cienia. | ||
| RLHF do synchronizacji | Wykorzystuje uczenie się przez wzmacnianie, aby udoskonalić synchronizację audiowizualną. | Eliminuje opóźnienia synchronizacji ruchu warg. |
| Funkcja | Google Veo 3 | OpenAI Sora | Pas startowy Gen-2 | Pika Labs |
| Maksymalna rozdzielczość | 1080p+ | 1080p | 720p | 1080p |
| Synchronizacja dźwięku | ✅ Natywny | ❌ Brak | ❌ Edycja ręczna | ❌ Brak |
| Świadomość 3D | ✅ Oparte na fizyce | ✅ Podstawowy | ❌ Ograniczona | ❌ Ograniczona |
| Modalności wprowadzania | Tekst + dźwięk + obraz | Tylko tekst | Tekst + obraz | Tekst + obraz |
| Możliwości edycji | ✅ Zaawansowane | ❌ Nie | ✅ Podstawowy | ✅ Podstawowy |